В разработке программного обеспечения массивы используются повсеместно. «Умные» типы данных в современных языках программирования, такие как, например, динамические массивы, предоставляют большие возможности для удобной работы с объектами. Но алгоритмы, лежащие в основе работы с этими типами данных, были разработаны на заре зарождения информатики — в середине двадцатого века. Первый алгоритм двоичного поиска был опубликован в 1946 году.
Рассмотрим самые популярные алгоритмы для работы с массивами.
Последовательный (линейный) поиск
Это самый простой алгоритм поиска значения в массиве. Использует метод поочередного сравнения элементов массива со значением ключа. Осуществляется обычно, слева направо. Используется, если элементов в массиве немного либо список не упорядочен. Абсолютно неэффективен в больших массивах, где обычно применяется двоичный поиск. Алгоритм работает следующим образом:
- Сравниваем значение ключа со значением элемента массива.
- Если значения равны, возвращаем полученное значение.
- Если нет – увеличиваем значение переменной цикла на единицу и сравниваем со следующим элементом массива.

Индексно-последовательный поиск
Более эффективный способ поиска значения в отсортированном массиве. Но более требовательный к ресурсам.
Бинарный поиск
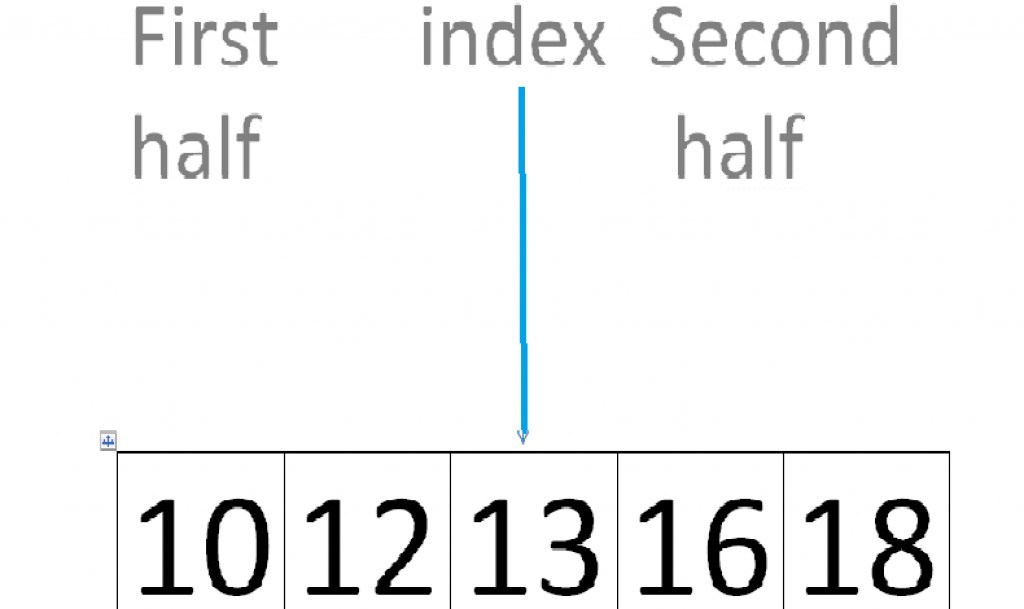
Двоичный (бинарный) поиск — это алгоритм нахождения элемента массива последовательным делением массива пополам и сравниванием исходного числа с числом из середины массива. Если число из середины меньше искомого, ищем далее, во второй части, если больше — продолжаем поиск в первой. Алгоритм самый быстрый из всех перечисленных и работает следующим образом:
- Сначала узнаем значение объекта в середине массива. Проверяем на соответствие с исходным значением.
- Если значение из середины меньше исходного, то продолжаем поиск во второй половине, если больше — ищем в первой.
- В получившейся половине поступаем таким же образом: делим ее на половину и сравниваем получившееся значение.
Поиск происходит до момента, пока исходное значение не станет равно значению в массиве. Если такого не происходит — значит данного значения в массиве нет.
Есть несколько подводных камней, которые могут встретиться при проектировании двоичного поиска.
Переполнение выбранного типа данных
Чтобы узнать значение в середине массива, необходимо сложить правое и левое значения, и разделить на два. То есть:
Середина массива = Левое значение + (Левое значение — Правое значение)/2
Здесь есть опасность переполнения типа данных при операции сложения. Если в массиве есть значения столь больших размеров, приходится использовать различные приемы, чтобы избежать риска. Ниже представлены стандартные ошибки при разработке двоичного поиска.
Ошибки значений
Или ошибки на единицу. Очень важно учесть следующие варианты:
- Пустой массив.
- Значение отсутствует.
- Выход за границы массива.
Несколько экземпляров
Необходимо учесть, что в случае существования в массиве нескольких одинаковых экземпляров ключа программа должна находить определенный (первый, последний, следующий за ним).
Разберем реализации данного алгоритма в языке программирования C плюс плюс. Необходимо учитывать, что двоичный поиск работает только с отсортированным массивом! Если массив предварительно не отсортировать, то результат вычислений будет неверным.
Ниже приведен код на C ++. Сначала инициализируется массив целочисленных переменных arr, размером десять. Далее оператор cin в цикле for ожидает ввода десяти значений от пользователя (строка десять).
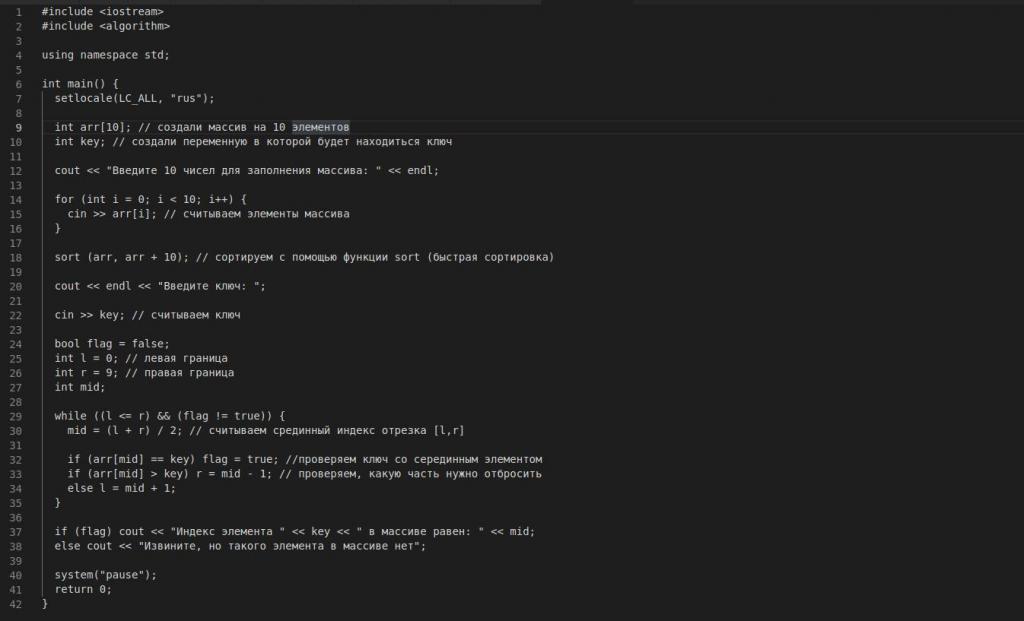
В двадцатой строке программа ждет от пользователя ввода значения ключа.
Строки 29 – 35 представляют собой реализованный алгоритм бинарного поиска. В ходе выполнения программы в переменную mid записывается значение среднего элемента по формуле:
Середина массива (mid) = (Левое значение (l) + Правое значение (r))/2
Строкой
arr[mid]==key
Проверяется, равно ли серединное значение значению ключа. Если равно, то значение переменной flag меняется на значение ИСТИНА, то есть задача решена.
Если же серединное значение больше значения нашего ключа, то правой части (переменная r) присваивается mid. Если наоборот, то mid кладется в r.
Последнее — это проверка булевой переменной flag.
Достоинства бинарного поиска
Двоичным поиском следует пользоваться, если нужна быстрая работа программы. И написать такой алгоритм не составит труда даже начинающему программисту. Но очень важно учитывать все крайние случаи: выход за пределы массива, отсутствие искомого значения, ошибка переполнения данных.
Недостатки
Для корректной работы алгоритма массив необходимо предварительно отсортировать. Для этого в языке программирования C++ можно воспользоваться готовой функцией sort(). И еще один важный момент, на который необходимо обратить внимание, изучая двоичный поиск в C и С++. Этот алгоритм можно использовать только с определенными структурами данных. Например, сюда не подойдут структуры, использующие связные списки.
Автор:




















