Все программисты знают о потенциальной угрозе переполнения буфера (buffer) в своих программах. Существует много угроз, связанных с ним, как в новом, так и в старом ПО, независимо от количества выполненных исправлений. Злоумышленники могут воспользоваться такой ошибкой, внедрив код, специально предназначенный для того, чтобы вызвать переполнение начальной части набора данных, а затем записать оставшиеся в адрес памяти, смежный с переполненным.
Данные могут содержать исполняемый код, который позволит злоумышленникам запускать более крупные и сложные программы или предоставлять им доступ к системе. Ошибку очень трудно найти и исправить, потому что ПО кода состоит из миллионов строк. Исправления этих ошибок довольно сложны и, в свою очередь, также подвержены ошибкам, что осложняет процесс устранения.
Определение переполнения буфера
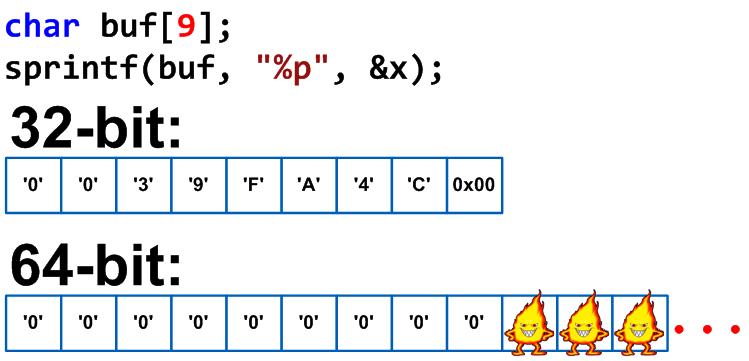
Прежде чем искать переполнение, нужно знать, что оно собой представляет. Как следует из названия, эти уязвимости связаны с буферами или выделением памяти в языках, обеспечивающих прямой низкоуровневый доступ к чтению и записи.
При применении языков C и Assembler чтение или запись таких распределений не влечет за собой автоматической проверки границ. В связи с чем, если обнаружено переполнение стекового буфера в данном приложении, не существует проверки на возможность помещения числа байтов в рассматриваемый буфер. В таких случаях программа может «переполнить» его емкость. Это приводит к тому, что данные, записываемые после наполнения, переписывают содержимое последующих адресов в стеке и считывают дополнительные. Переполнение может произойти непреднамеренно из-за ошибок пользователя.
Бывает, что оно вызвано тем, что злонамеренный субъект посылает тщательно созданный вредоносный ввод в программу, которая затем пытается сохранить его в недостаточный буфер. Если при этом будет обнаружено переполнение стекового буфера в данном приложении, избыточные данные записываются в соседний, где перезаписывают любые имеющиеся данные.
Обычно они содержат указатель возврата эксплуатируемой функции — адрес, по которому процесс должен перейти дальше. Злоумышленник может установить новые значения, чтобы они указывали на адрес по выбору. Атакующий обычно устанавливает новые значения, чтобы обозначить место, где расположена полезная нагрузка. Это изменяет путь выполнения процесса и мгновенно передает управление вредоносному коду.
Использование переполнения буфера позволяет злоумышленнику контролировать или завершать работу процесса либо изменять его внутренние переменные. Это нарушение занимает место в топ-25 наиболее опасных программных ошибок мира (2009 CWE/SANS Top 25 Most Dangerous Programming Errors) и определяется как CWE-120 в словаре перечислений слабых системных мест. Несмотря на то что они хорошо изучены, они продолжают наносить вред популярным программам.
Простой вектор использования буфера
При работе с исходным кодом нужно обратить особое внимание, где буферы используются и модифицируются. Особо следует отметить функции, относящиеся к вводу, предоставленному пользователем или другим внешним источником, поскольку они обеспечивают простой вектор для использования, когда обнаружено переполнение стекового буфера. Например, когда юзер задает вопрос «да» или «нет», целесообразно сохранить строковые данные пользователя в небольшом buffer для строки «да», как показано в следующем примере.

Глядя на код, видно, что проверка границ не выполняется. Если пользователь вводит «возможно», то программа будет аварийно завершать работу, а не запрашивать у него ответ, который записывается в buffer независимо от его длины. В этом примере, поскольку user answer является единственной объявленной переменной, следующие значения в стеке будут значением обратного адреса или местом в памяти, куда программа вернется после выполнения функции ask Question.
Это означает, что если юзер вводит четыре байта данных, что достаточно для переполнения буфера команд клиента, последует действительный адрес возврата, который будет изменен. Это заставит программу выйти из функции в другой точке кода, чем первоначально предполагалось, и может привести к тому, что ПО будет вести себя опасным и непреднамеренным образом.
Если первым шагом для обнаружения переполнения буфера в исходном коде является понимание того, как они работают, вторым этапом является изучение внешнего ввода и манипуляций с буфером, то третьим шагом будет необходимость узнать, какие функции подвержены этой уязвимости и какие могут действовать как «красные флаги». Функция gets отлично подходит для записи за пределами предоставленного ей buffer. На самом деле это качество распространяется на все семейство связанных возможностей, включая strcpy, strcmp и printf/sprintf, везде, где используется одна из этих функций уязвимости переполнения.
Удаление из кодовой базы
Если обнаружено переполнение стекового буфера в исходном коде, потребуется согласованное удаление их из базы. Для этого надо быть знакомым с безопасными методами работы. Самый простой способ предотвратить эти уязвимости — использовать язык, который их не допускает. Язык C имеет эти уязвимости благодаря прямому доступу к памяти и отсутствию строгой типизации объектов. Языки, не разделяющие эти аспекты, обычно неуязвимы. Это Java, Python и .NET, наряду с другими языками и платформами, не требующими специальных проверок или изменений.
Конечно, не всегда возможно полностью изменить язык разработки. В этом случае используют безопасные методы для работы с переполнением буфера команд. В случае функций обработки строк было много дискуссий о том, какие методы доступны, какие безопасны в использовании, а каких следует избегать. Функции strcpy и strcat копируют строку в буфер и добавляют содержимое одного в другой. Эти два метода демонстрируют небезопасное поведение, поскольку не проверяют границы целевого buffer, и выполняют запись за пределами, если для этого достаточно байтов.
Альтернативная защита
Одной из часто предлагаемых альтернатив являются связанные версии, которые записывают в максимальный размер целевого буфера. На первый взгляд это выглядит как идеальное решение. К сожалению, у этих функций есть небольшой нюанс, который вызывает проблемы. При достижении предела, если завершающий символ не помещается в последний байт, возникают серьезные сбои при чтении буфера.

В этом упрощенном примере видна опасность строк, не оканчивающихся нулем. Когда foo помещается в normal buffer, он завершается нулем, поскольку имеет дополнительное место. Это лучший вариант развития событий. Если байты в переполнения буфера на стеке будут в другом символьном buffer или другой печатаемой строке, функция печати продолжить чтение, пока не будет достигнут завершающий символ этой строки.
Недостаток заключается в том, что язык C не предоставляет стандартную, безопасную альтернативу этим функциям. Тем не менее имеется и позитив — доступность нескольких реализаций для конкретной платформы. OpenBSD предоставляет strlcpy и strlcat, которые работают аналогично функциям strn, за исключением того, что они усекают строку на один символ раньше, чтобы освободить место для нулевого терминатора.
Аналогично Microsoft предоставляет свои собственные безопасные реализации часто используемых функций обработки строк: strcpy_s, strcat_s и sprintf_s.
Использование безопасных альтернатив, перечисленных выше, является предпочтительным. Когда это невозможно, выполняют ручную проверку границ и нулевое завершение при обработке строковых буферов.
Уязвимости компиляции

В случае если небезопасная функция оставляет открытую возможность переполнение буфера C, то не все потеряно. При запуске программы компиляторы часто создают случайные значения, известные как канарейки (canary), и помещают их в стек, поэтому представляют опасность. Проверка значения канарейки по отношению к ее первоначальному значению может определить, произошло ли переполнение буфера Windows. Если значение было изменено, программа будет закрыта или перейдет в состояние ошибки, а не к потенциально измененному адресу возврата.
Некоторые современные операционные системы предоставляют дополнительную защиту от переполнения буфера в виде неисполнимых стеков и рандомизации размещения адресного пространства (ASLR). Неисполняемые стеки — предотвращение выполнения данных (DEP) — помечают стек, а в некоторых случаях другие структуры как области, где код не будет выполнен. Это означает, что злоумышленник не может внедрить код эксплойта в стек и ожидать его успешного выполнения.
Перед тем как исправить переполнение буфера, распаковывают на ПК ASLR. Он был разработан для защиты от ориентированного на возврат программирования как обходной путь к неисполнимым стекам, где существующие фрагменты кода объединены в цепочку на основе смещения их адресов.
Он работает путем рандомизации областей памяти структур, так что их смещения сложнее определить. Если бы эта защита существовала в конце 1980-х годов, червя Морриса можно было бы не допустить. Это связано с тем, что он функционировал частично, заполняя буфер в протоколе UNIX finger кодом эксплойта, а затем переполнял его, чтобы изменить адрес возврата и указывал на заполненный буфер.
ASLR и DEP усложняют точное определение адреса, который нужно указать, выполняя эту область памяти полностью нерабочей. Иногда уязвимость проскальзывает сквозь трещины, открытые для атаки переполнения буфера, несмотря на наличие элементов управления на уровне разработки, компилятора или операционной системы.
Статический анализ покрытия
В ситуации переполнения buffer есть две решающие задачи. Во-первых, необходимо определить уязвимость и изменить кодовую базу для решения проблемы. Во-вторых, обеспечивают замену всех версий кода уязвимости переполнения буфера. В идеале это начнется с автоматического обновления всех подключенных к интернету систем.
Нельзя предполагать, что такое обновление обеспечит достаточный охват. Организации или частные лица могут использовать программное обеспечение в системах с ограниченным доступом к интернету, требующих ручного обновления. Это означает, что новости об обновлении должны быть распространены среди любых администраторов, которые могут использовать ПО, а патч должен быть легкодоступен для загрузки. Создание и распространение исправлений выполняют как можно ближе к обнаружению уязвимости, что обеспечивает минимизацию времени уязвимости.
Благодаря использованию безопасных функций обработки буфера и соответствующих функций безопасности компилятора и операционной системы можно создать надежную защиту от переполнения buffer. С учетом этих шагов последовательная идентификация недостатков является решающим шагом для предотвращения эксплойта.
Комбинирование строк исходного кода в поисках потенциальных угроз может быть утомительным. Кроме того, всегда есть вероятность, что человеческие глаза могут пропустить что-то важное. Инструменты статического анализа используются для обеспечения качества кода, были разработаны специально для обнаружения уязвимости безопасности во время разработки.
Статический анализ покрытия устанавливает «красные метки» для потенциальных переполнений buffer. Затем их обрабатывают и исправляют отдельно, чтобы вручную не искать в базе. Эти инструменты в сочетании с регулярными проверками и знанием того, как устранить переполнения, позволяют выявлять и устранять подавляющее большинство недостатков до завершения разработки ПО.
Выполнение атаки через root
Ошибки кодирования обычно являются причиной переполнения buffer. Распространенные ошибки при разработке приложений, которые могут привести к нему, включают в себя неспособность выделить достаточно большие буферы и отсутствие механизма проверки этих проблем. Такие ошибки особенно проблематичны в языках C/C++, которые не имеют встроенной защиты от переполнения и часто являются объектами атак переполнения буфера.
В некоторых случаях злоумышленник внедряет вредоносный код в память, которая была повреждена из-за переполнения стекового буфера. В других случаях просто используют преимущества повреждения соседней памяти. Например, программа, которая запрашивает пароль пользователя для предоставления ему доступа к системе. В приведенном ниже коде правильный пароль предоставляет привилегии root. Если пароль неверный, программа не предоставляет юзеру привилегии.
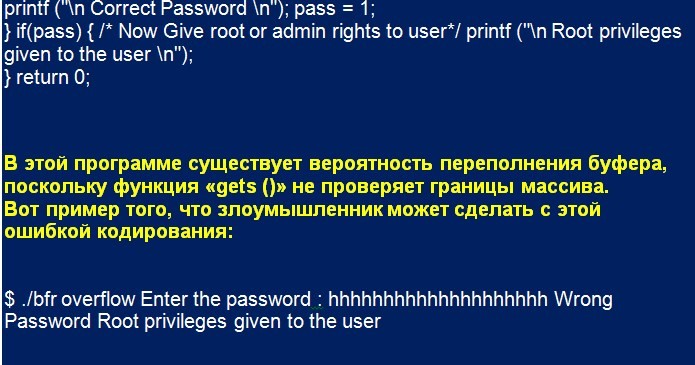
В приведенном примере программа предоставляет пользователю привилегии root, даже если он ввел неверный пароль. В этом случае злоумышленник предоставляет вход, длина которого больше, чем может вместить буфер, создавая переполнение, перезаписывающего память целого числа pass. Поэтому, несмотря на неверный пароль, значение pass становится ненулевым, и злоумышленник получает права root.
Атака временной области хранения
Буфер представляет собой временную область для хранения данных. Когда программа или системный процесс размещает больше данных чем было изначально выделено для хранения, дополнительные переполняются. Это приводит к тому, что некоторые из них просачиваются в другие buffer, повреждают или перезаписывают данные.
При атаке с переполнением дополнительные данные содержат специальные инструкции для действий, предназначенных хакером или злонамеренным пользователем, например, они вызывают ответ, который повреждает файлы, изменяет данные или раскрывает личную информацию.
Злоумышленник использует эксплойт с переполнением, чтобы воспользоваться программой, ожидающей ввода пользователя. Существует два типа переполнения buffer: на основе стека и кучи. Основанные на куче трудны для выполнения и наименее распространенные, при этом атакуют приложение, заполняя пространство, зарезервированное для программы.
Стек — пространство памяти, используемое для хранения пользовательского ввода. Такое переполнение чаще встречается у злоумышленников, использующих приложения.
Современные компиляторы обычно предоставляют возможность проверки переполнения во время компиляции/компоновки, но во время выполнения довольно сложно проверить эту проблему без какого-либо дополнительного механизма защиты обработки исключений.

Варианты работы программы:
- Ввод: 12345678 (8 байт), программа работает без сбоев.
- Ввод: 123456789 (9 байт), появится сообщение «Ошибка сегментации», программа завершается.
Уязвимость существует из-за переполнения, если пользовательский ввод argv превышает 8 байтов. Для 32-битной системы (4 байта) заполняют память двойным словом (32 бита). Размер символа составляет 1 байт, поэтому если запросить буфер с 5 байтами, система выделит 2 двойных слова (8 байтов). Вот почему при вводе более 8 байтов Buffer будет переполнен.
Подобные стандартные функции, которые технически менее уязвимы, существуют. Например, strncpy (), strncat () и memcpy (). Проблема с этими функциями заключается в том, что ответственность за определение размера буфера лежит на программисте, а не на компиляторе.
Каждый программист C/C++ должен знать проблему прежде чем начинать кодирование. Многие генерируемые проблемы в большинстве случаев могут быть защищены от переполнения.
Опасности в C/C++

Пользователи C должны избегать применения опасных функций, которые не проверяют границы, если они не уверены, что границы не будут превышены. Функции, которых следует избегать в большинстве случаев, чтобы обеспечить защиту, включают функции strcpy. Их следует заменить такими функциями, как strncpy. Следует избегать использования функции strlen, если пользователь уверен, что будет найден завершающий символ NIL. Семейство scanf (): scanf (3), fscanf (3), sscanf (3), vscanf (3), vsscanf (3) и vfscanf (3) — опасно для использования, его не применяют для отправки данных в строку без контроля максимальной длины, «формат% s» является особенно распространенным сбоем.
Официально snprintf () не является стандартной функцией C в классификации ISO 1990. Эти системы не защищают от переполнения буфера, они просто вызывают sprintf напрямую. Известно, что текущая версия Linux snprintf работает правильно, то есть фактически соблюдает установленную границу. Возвращаемое значение snprintf () также меняется.
Версия 2 спецификации Unix (SUS) и стандарт C99 отличаются тем, что возвращает snprintf (). Некоторые версии snprintf don’t гарантируют, что строка закончится в NIL, а если строка слишком длинная, она вообще не будет содержать NIL. Библиотека glib имеет g_snprintf () с последовательной семантикой возврата, всегда заканчивается NIL и, что наиболее важно, всегда учитывает длину буфера.
Переполнение буфера коммуникационного порта
Иногда последовательный порт сообщает о переполнении buffer. Эта проблема может быть вызвана несколькими факторами. К ним относятся скорость компьютера, скорость передачи используемых данных, размер FIFO последовательного порта и размер FIFO устройства, который передает данные на последовательный порт.
Управление потоком будет ждать, пока в буфере не появится определенное количество байтов, прежде чем процессор отправит сообщение или сигнал другому устройству для прекращения передачи. При более высоких скоростях передачи последовательный порт будет получать несколько байтов с момента достижения уровня управления потоком буфера и прекращения передачи прибора.
Эти дополнительные байты будут больше, если процесс с высоким приоритетом контролирует процессор цели в реальном времени. Поскольку процесс переполнения буфера коммуникационного порта имеет более высокий приоритет, чем прерывание VISA, процессор не будет предпринимать никаких действий, пока такой не будет завершен в реальном времени.
Настройки VISA и Windows по умолчанию для 16-байтового FIFO составляют 14 байтов, оставляя 2 байта в FIFO, когда устройство пытается отправить сообщение от источника. При более высоких скоростях передачи на медленных компьютерах возможно получить более 4 байтов в момент, когда последовательный порт запрашивает процессор, посылая сигнал о прекращении передачи.
Чтобы решить проблему, когда обнаружено переполнение стекового буфера в Windows 10, нужно открыть диспетчер устройств. Затем найти COM-порт, для которого изменяют настройки, и открыть свойства. Далее нажимают на вкладку «Дополнительно», появится ползунок, которым изменяют размер переполнения буфера обмена, чтобы UART быстрее включил управление потоком.
Значение по умолчанию в большинстве случаев достаточно. Однако если поступает ошибка переполнения buffer, уменьшают значение. Это приведет к тому, что большее количество прерываний будет отправлено процессору с замедлением байтов в UART.
Методы безопасной разработки
Методы безопасной разработки включают регулярное тестирование для обнаружения и устранения переполнения. Самый надежный способ избежать или предотвратить его — использовать автоматическую защиту на уровне языка. Другое исправление — проверка границ во время выполнения, которая предотвращает переполнение, автоматически проверяя, что данные, записанные в буфер, находятся в допустимых границах.
Облачная служба Veracode выявляет уязвимости кода, такие как переполнение buffer, поэтому разработчики устраняют их до того, как они будут использованы. Уникальная в отрасли запатентованная технология тестирования безопасности бинарных статических приложений (SAST) Veracode анализирует его, включая компоненты с открытым исходным кодом и сторонние, без необходимости доступа к нему.
SAST дополняет моделирование угроз и обзоры кода, выполняемые разработчиками, быстрее и с меньшими затратами обнаруживая ошибки и упущения в коде за счет автоматизации. Как правило, он запускается на ранних этапах жизненного цикла разработки ПО, поскольку проще и дешевле устранять проблемы, прежде чем приступать к производственному развертыванию.
SAST выявляет критические уязвимости, такие как внедрение SQL, межсайтовый скриптинг (XSS), ошибку переполнения буфера, необработанные состояния ошибок и потенциальные закоулки. Кроме того, двоичная технология SAST предоставляет полезную информацию, которая определяет приоритеты в зависимости от серьезности и предоставляет подробную инструкцию по исправлению.
Уязвимость переполнения buffer существует уже почти 3 десятилетия, но она по-прежнему обременительна. Хакеры по всему миру продолжают считать ее своей тактикой по умолчанию из-за огромного количества восприимчивых веб-приложений. Разработчики и программисты затрачивают огромные усилия для борьбы с этим злом IT-технологий, придумывая все новые и новые способы.
Основная идея последнего подхода заключается в реализации инструмента исправления, который делает несколько копий адресов возврата в стеке, а затем рандомизирует расположение всех копий в дополнение к количеству. Все дубликаты обновляются и проверяются параллельно, так что любое несоответствие между ними указывает на возможную попытку атаки и вызывает исключение.
Автор:



















